Chapitre 4 : Phonologie
4.7 Règles phonologiques
Éliminer la redondance par la fidélité
Si nous rédigeons notre analyse des sonantes en français comme des descriptions de la prononciation des trois phonèmes, nous obtenons des énoncés comme ceux-ci :
- /m/ se prononce comme [m̥] en fin de mot après une obstruante non voisée
- /m/ se prononce comme [m] ailleurs
- /l/ se prononce comme [l̥] en fin de mot après une obstruante non voisée
- /l/ se prononce comme [l] ailleurs
- /ʀ/ se prononce comme [ʀ̥] en fin de mot après une obstruante non voisée
- /ʀ/ se prononce comme [ʀ] ailleurs
Notez la grande redondance dans ces énoncés. Premièrement, chaque phonème /X/ a une formulation identique : « /X/ se prononce [X] ailleurs ». Cette similitude découle de notre choix de représenter le phonème en utilisant le même symbole que l’allophone par défaut. Si nous procédons de la sorte pour chaque phonémisation, nous aurons toujours ce type d’énoncé pour la prononciation par défaut de chaque phonème.
Comme nous aurons toujours cet énoncé par défaut, il n’est pas nécessaire de le mentionner explicitement. Au lieu de cela, nous pouvons simplement considérer qu’il s’agit d’un élément inhérent au fonctionnement de la phonologie : chaque phonème est toujours prononcé comme l’allophone par défaut qui lui correspond « ailleurs ». C’est ce que l’on appelle parfois le principe de fidélité : si un phonème apparaît dans un environnement qui n’est couvert par aucun autre énoncé concernant la prononciation de ce phonème, alors il est prononcé de la même manière (sa prononciation est « fidèle » à son phonème). Ainsi, nous pouvons supprimer chaque occurrence de cet énoncé par défaut et nous appuyer plutôt sur le principe de fidélité pour déterminer de manière générale les allophones par défaut de chaque phonème dans toutes les langues parlées. Il nous reste donc les trois énoncés suivants pour le français :
- /m/ se prononce comme [m̥] en fin de mot après une obstruante non voisée
- /l/ se prononce comme [l̥] en fin de mot après une obstruante non voisée
- /ʀ/ se prononce comme [ʀ̥] en fin de mot après une obstruante non voisée
Éliminer la redondance par des classes naturelles
Il reste encore de la redondance. Ces trois énoncés ont la même forme : « /X/ se prononce [X̥] en fin de mot après une obstruante non voisée ». Il s’agit d’un autre schéma, et une partie de la phonologie (et de la linguistique en général) consiste à trouver des schémas et à les réduire à des descriptions et à des explications plus simples.
Veuillez noter que /m/, /l/ et /ʀ/ sont des sonantes. Il s’agit d’un début de classe naturelle, mais les classes naturelles doivent être exhaustives, et il existe d’autres sonantes en français. Par exemple, nous voyons [n] et [j] dans les données, et il s’agit vraisemblablement d’allophones de /n/ et /j/, qui devraient être inclus dans toute classe naturelle de phonèmes sonores. Cela nous laisse deux options : soit il existe trois énoncés indépendants concernant certaines sonantes, à savoir /m/, /l/ et /ʀ/, qui ont toutes par coïncidence la même forme de base, soit il existe un énoncé unique que nous pouvons formuler et qui englobe toutes les sonantes, y compris /n/ et /j/.
Chaque option fait une prédiction différente sur la prononciation du français. Si /m/, /l/ et /ʀ/ se comportent de manière totalement indépendante de /n/ et /j/, alors nous prédisons que /n/ et /j/ n’auront pas d’allophones non voisés s’ils sont en fin de mot après une obstruante non voisée. S’il existe au contraire un modèle unique qui s’applique à toutes les sonantes, nous prévoyons que /n/ et /j/ devraient avoir des allophones non voisés exactement dans les mêmes environnements que /m/, /l/ et /ʀ/.
Rien dans les données fournies ne peut nous aider à décider entre ces deux options, car il n’y a pas de mots comportant /n/ ou /j/ dans l’environnement pertinent dans les données. En fait, la phonotactique en français empêche que cela se produise de toute façon, et nous ne pouvons donc malheureusement jamais tester nos prédictions!
Éliminer la redondance par la simplicité
Puisque nous avons deux analyses concurrentes qui expliquent les données fournies, et qu’aucune autre donnée ne contredit l’une ou l’autre analyse, nous pouvons suivre le principe de simplicité et choisir l’analyse qui contient le moins d’énoncés. Cela nous permet de simplifier nos trois énoncés en un seul :
- Une sonante se prononce comme étant non voisée en fin de mot après une obstruante non voisée.
Vous remarquerez que cette formulation ne fait aucune référence au lieu ni au mode d’articulation des sonantes, mais uniquement à leur phonation. Nous devrions supposer que des énoncés tels que ceux-ci n’affectent que ce qu’ils déclarent explicitement; tout le reste doit rester fidèle (inchangé). Nous ne voulons pas que /m/ se transforme en un quelconque phone non voisé! Nous voulons précisément qu’il soit prononcé comme [m̥], de sorte que seule sa phonation diffère.
Écrire les règles phonologiques
Ces types d’énoncés sont souvent appelés règles phonologiques, et il existe une notation abrégée permettant de les réduire à une forme plus facile à traiter. Nous pouvons utiliser une flèche  ;pour remplacer « se prononce comme » et utiliser une barre oblique / pour séparer cette transformation phonétique de l’environnement dans lequel la règle s’applique. Enfin, nous pouvons remplacer la description verbeuse de l’environnement « en fin de mot après une obstruante non voisée » par la notation simplifiée que nous avons utilisée dans les diagrammes de phonèmes. Nous utilisons un trait de soulignement ▁ pour représenter la position dans l’environnement où le phonème doit se trouver pour être soumis à la règle et le symbole du croisillon # pour indiquer les frontières des mots.
;pour remplacer « se prononce comme » et utiliser une barre oblique / pour séparer cette transformation phonétique de l’environnement dans lequel la règle s’applique. Enfin, nous pouvons remplacer la description verbeuse de l’environnement « en fin de mot après une obstruante non voisée » par la notation simplifiée que nous avons utilisée dans les diagrammes de phonèmes. Nous utilisons un trait de soulignement ▁ pour représenter la position dans l’environnement où le phonème doit se trouver pour être soumis à la règle et le symbole du croisillon # pour indiquer les frontières des mots.
Cela nous donne la règle abrégée suivante :
- sonante non voisée / obstruante non voisée ▁ #
Il existe des moyens plus avancés de simplifier les règles phonologiques, mais pour les besoins de ce manuel, cette forme sera suffisante. Nous disposons maintenant du modèle de base suivant pour une règle phonologique comprenant trois éléments clés : la cible (indiquée ici par A), le changement (B), et l’environnement (C ▁ D).
A B / C ▁ D
La cible d’une règle phonologique est la classe naturelle de phonèmes qui subissent une transformation pour se convertir en leurs allophones appropriés. Le changement causé par une règle phonologique fait référence à l’ensemble des propriétés phonétiques qui décrivent comment les allophones diffèrent de manière cohérente des phonèmes cibles. Enfin, l’environnement est le même que celui que nous avons utilisé pour traiter de la distribution des allophones. Comme nous l’avons vu, la plupart des environnements ne font référence qu’à des éléments situés immédiatement à gauche et/ou immédiatement à droite, bien que des environnements plus complexes soient possibles.
Phonologie générative et niveaux de représentation
Dans certaines versions de la phonologie, les phonèmes, les allophones et les règles phonologiques ne sont pas simplement des descriptions pratiques de schémas, mais des objets essentiels de la théorie, parfois proposés pour représenter certains aspects de la réalité cognitive. L’une des versions les plus courantes de la phonologie est la phonologie générative, qui a émergé dans les années 1950 et 1960 (Chomsky 1951, Chomsky et al. 1956, Halle 1959, Chomsky et Halle 1968). Cette approche s’appuie sur des idées développées au cours de la première moitié du 20e siècle (Saussure 1916, Bloomfield 1939, Swadesh et Voegelin 1939, Trubetzkoy 1939, Jakobson 1942, Harris 1946/1951, Wells 1949) et reflète finalement des idées issues des travaux de Dakṣiputra Pāṇini, un grammairien de l’Inde ancienne (vers 500 av. J.-C.) qui a développé des concepts et des méthodes d’analyse du sanskrit que l’on trouve encore dans la linguistique moderne.
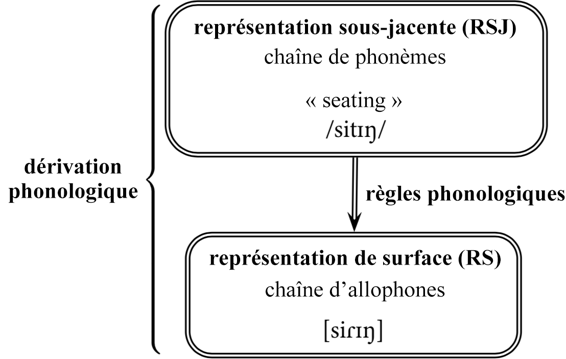
Dans la phonologie générative, les mots ont au moins deux formes phonologiques distinctes. La première est une approximation de la prononciation (étroite ou large, selon les besoins), que nous avons représentée entre crochets avec des phones. Cette représentation est appelée représentation de surface (RS) ou représentation phonétique. Étant donné qu’elle est composée de phones, la RS est une représentation relativement concrète, quelque chose de directement observable et mesurable. Ici, toutes les données que nous avons examinées sont décrites à l’aide de RS.
La seconde représentation est constituée de phonèmes et se nomme la représentation sous-jacente (RSJ) ou représentation phonémique. Puisque la RSJ est constituée de phonèmes, elle représente un objet abstrait dans nos analyses théoriques d’une langue. Comme pour les phonèmes, la question de savoir si les RSJ correspondent également à une quelconque réalité cognitive est débattue, mais que ce soit le cas ou non, elles constituent des outils utiles pour décrire la phonologie d’une langue. Ici, nous devrions réécrire toutes nos données en utilisant des phonèmes au lieu d’allophones.
Ainsi, pour chaque mot en géorgien, nous remplacerions chaque [l] clair par son phonème /ɫ/. Ainsi, les RSJ de [t͡ʃoli] (« wife ») et [xeli] (« hand ») seraient /t͡ʃoɫi/ et /xeɫi/.
De même, pour obtenir les RSJ des données en français, nous remplacerions toutes les sonantes non voisées par leurs phonèmes correspondants : la RSJ de [ɛtʀ̥] (« to be ») serait /ɛtʀ/, celle de [pœpl̥] (« people ») serait /pœpl/ et celle de [ʀitm̥] (« rythm ») serait /ʀitm/. Remarquez que les RSJ sont encadrées par des barres obliques, car elles sont constituées de phonèmes.
En phonologie générative, la relation entre les RSJ et les RS n’est pas simplement un lien statique. Au lieu de cela, les RSJ sont traitées comme des intrants dans un processus qui « génère » les RS en tant qu’extrants, en transformant activement les phonèmes en allophones appropriés. Ce modèle est conçu pour imiter le fonctionnement présumé du langage : nous commençons par une représentation mentale d’un mot dans notre esprit, puis, plus tard, nous articulons ce mot. Ce processus global est appelé dérivation phonologique, et les composantes individuelles de ce processus qui modifient les phonèmes sont nos règles phonologiques. Ce modèle est représenté graphiquement dans le diagramme qui suit.
Vérifiez votre compréhension
À venir!
Références
Bloomfield, Leonard. 1939. Menomini morphophonemics. In Études phonologiques dédiées à la mémoire de M. le prince N. S. Trubetzkoy, vol. 8, 105–115. Jednota českých matematiků a fyziků.
Chomsky, Noam. 1951. The morphophonemics of Modern Hebrew. Master’s thesis, University of Pennsylvania, Philadelphia.
Chomsky, Noam and Morris Halle. 1968. The sound pattern of English. New York: Harper & Row.
Chomsky, Noam, Morris Halle, and Fred Lukoff. 1956. On accent and juncture in English. In For Roman Jakobson: Essays on the occasion of his sixtieth birthday, ed. Morris Halle, Horace Lunt, Hugh MacLean, and Cornelis van Schooneveld, 65–80. The Hague: Mouton.
Halle, Morris. 1959. The sound pattern of Russian: A linguistic and acoustical investigation. The Hague: Mouton.
Harris, Zellig S. 1946/1951. Methods in structural linguistics. Chicago: University of Chicago Press.
Jakobson, Roman. 1942. The concept of phoneme. In On language, ed. Linda R. Waugh and Monique Moville-Burston, 218–241. Cambridge, MA: Harvard University Press.
Saussure, Ferdinand de. 1916. Cours de linguistique générale. Paris: Payot.
Swadesh, Morris et Charles F. Voegelin. 1939. A problem in phonological alternation. Language 15: 1–10.
Trubetzkoy, Nikolai Sergeyevich. 1939. Grundzüge der Phonologie, Travaux du Cercle linguistique de Prague, vol. 7. Prague: Jednota českých matematiků a fyziků.
Wells, Rulon S. 1949. Automatic alternations. Language 25(2): 99–116.
