Chapitre 4 : Phonologie
4.6 Autre exemple d’analyse phonémique
Plus de deux phones d’intérêt
Le cas du géorgien est un exemple assez simple, avec seulement deux phones d’intérêt et des distributions et similitudes phonétiques assez évidentes. Cependant, nous rencontrons souvent des cas plus difficiles, peut-être parce qu’il y a beaucoup de phones d’intérêt ou parce que les distributions et/ou la similitude phonétique peuvent être moins claires.
Considérons les données suivantes sur la façon dont certains locuteurs prononcent le français (une langue romane occidentale de la famille indo-européenne, parlée en France et ailleurs dans le monde; données adaptées de Katamba 1989). Les phones concernés sont les sonantes voisées [m] [l] et [ʀ] et les sonantes non voisées [m̥] [l̥] et [ʀ̥]. Notez que [ʀ] représente une consonne roulée uvulaire voisée et que le diacritique [ ; ̥] indique que le phone est non voisé.
| [ʀym] | rhume | [il] | île |
| [mɛʀ] | mère | [tabl] | table |
| [tɛʀm] | terme | [kasabl] | cassable |
| [film] | film | [ɛl] | elle |
| [limite] | limité | [klemã] | clément |
| [liʀ] | lire | [simetʀikmã] | symétriquement |
| [lɛvʀ] | lèvre | [ɛtʀ̥] | être |
| [plɛziʀ] | plaisir | [ʃifʀ̥] | chiffre |
| [tʀivjal] | trivial | [mɛtʀ̥] | mettre |
| [ʀali] | rallye | [mɛkɔnɛtʀ̥] | méconnaître |
| [ʀymatismal] | rhumatismal | [pœpl̥] | peuple |
| [ʀɔ̃fle] | ronfle | [ɔ̃kl̥] | oncle |
| [ekʀiʀ] | écrire | [tãpl̥] | temple |
| [tɔʀdʀ] | tordre | [ʀitm̥] | rythme |
| [pɛʀs] | Perse | [ʀymatism̥] | rhumatisme |
Il ne reste plus qu’à suivre les mêmes étapes que pour le géorgien.
Étape 1 : Identifier et organiser les phones d’intérêt
Ici, nous avons beaucoup de données à trier, et six phones à prendre en compte. Mais les phones se séparent proprement en trois paires ([m]-[m̥] [l]-[l̥] et [ʀ]-[ʀ̥]) ou en deux triplets ([m]-[l]-[ʀ] et [m̥]-[l̥]-[ʀ̥]). Comme il est généralement plus facile d’analyser une paire, nous pouvons commencer par une seule paire et voir si nous pouvons trouver des modèles. Nous choisirons d’abord [m] et [m̥].
Étape 2 : Identifier les environnements individuels des phones d’intérêt
Pour chaque phone de la paire choisie, nous notons les niveaux individuels dans lesquels il apparaît, mot par mot (encore une fois, à un niveau d’initiation, nous ne devrons normalement jamais prendre en considération que les environnements immédiats de droite et de gauche). Ainsi, pour [ʀym] « rhume », on inscrira y▁# dans la colonne [m], car [ʀym] a [m] entre [y] et la fin du mot. Ensuite, pour le mot suivant [mɛʀ] « mère », on inscrira#▁ɛdans la colonne [m]. Et ainsi de suite, jusqu’à ce que nous obtenions la liste complète suivante d’environnements :
| [m] | [m̥] |
|---|---|
| y▁# | t▁# |
| #▁ɛ | s▁# |
| ʀ▁# | |
| l▁# | |
| i▁i | |
| y▁a | |
| s▁a | |
| e▁ã | |
| i▁e | |
| k▁ã |
Étape 3 : Déterminer le chevauchement des environnements
Pour vérifier si les phones sont en distribution contrastive, il faut voir s’il y a un chevauchement des environnements sur les deux listes. Si les deux phones ont exactement les mêmes environnements, il y a de fortes chances qu’il s’agisse d’allophones de phonèmes distincts.
Il n’y a pas de jumelages exacts, mais nous constatons des similitudes dans certains environnements de gauche et de droite. Par exemple, nous voyons que [m] et [m̥] apparaissent tous deux après [s]. Cependant, le [m] voisé ne le fait que lorsqu’il est suivi de la voyelle [a], comme dans [ʀymatismal] « rhumatismal », tandis que le [m̥] non voisé ne le fait qu’en fin de mot, comme dans [ʀymatism̥] « rhumatisme ».
De même, nous constatons que [m] et [m̥] se produisent tous deux en fin de mot, mais avec des restrictions. Le [m] voisé n’est final de mot que lorsqu’il est précédé de [y] ou de [l], comme dans [ʀym] « rhume » et [film] « film », tandis que le [m̥] non voisé n’est final de mot que lorsqu’il est précédé de [t] ou de [s], comme dans [ʀitm̥] « rythme » et [ʀymatism̥] « rhumatisme ». Ce n’est probablement pas une coïncidence si la différence de voisement des deux phones en question correspond au voisement du phone à sa gauche dans ces cas.
Étant donné qu’il existe des modèles apparents de répartition de ces deux phones, et qu’ils ne peuvent pas se trouver dans les mêmes environnements, il semble qu’ils ne soient pas répartis de manière contrastée, et nous passerions donc à l’étape 4.
Étape 4 : Simplifier les environnements
Il n’y a pas beaucoup d’éléments sur lesquels s’appuyer, car il y a très peu de données pour [m̥], mais il semble que les côtés gauche et droit comptent pour la distribution de [m̥], puisqu’il a systématiquement une classe naturelle à gauche (obstruantes non voisées) et une frontière de mot à droite. La distribution de [m] n’a pas grand-chose à voir avec la réalité, puisqu’elle comporte un mélange de diverses classes naturelles de part et d’autre. Pour commencer, nous pourrions dire que [m̥] n’apparaît qu’en fin de mot lorsqu’il est immédiatement précédé d’une obstruante non voisée, alors que [m] apparaît soit après les phones voisés (indépendamment de ce qui suit), soit avant n’importe quel phone (c’est-à-dire qu’il n’est pas en fin de mot). Il s’agit de la distribution complémentaire.
Étape 5 : Organiser les phones en phonèmes
Puisque [m̥] et [m] semblent avoir une distribution complémentaire et sont phonétiquement similaires (ce sont tous deux des occlusives nasales bilabiales, ne différant que par la phonation), il semble raisonnable d’analyser [m̥] et [m] comme des allophones d’un même phonème.
Étape 6 : Identifier l’allophone par défaut et achever l’analyse
L’allophone par défaut semble être [m], puisqu’il apparaît dans deux environnements distincts, alors que [m̥] n’apparaît que dans un seul. Ainsi, nous proposerions un phonème unique/m/avec deux allophones : [m̥] se produisant en fin de mot lorsqu’il est immédiatement précédé d’une obstruante non voisée (abrégée ici vlsobs▁#) et [m] se produisant ailleurs par défaut.
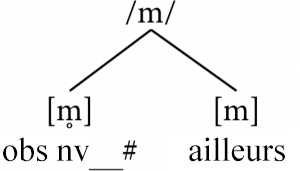
Répétez les étapes 2 à 6 pour [l] et [l̥]
Cette analyse semble raisonnable et nous pouvons donc continuer à travailler par paires sur les phones qui nous intéressent. La paire suivante à analyser est [l] et [l̥], nous revenons donc en arrière et répétons les étapes 2 à 6. Cela nous donne la liste suivante d’environnements pour [l] et [l̥] :
| [l] | [l̩] |
|---|---|
| i▁m | p▁# |
| #▁i | k▁# |
| #▁ɛ | |
| p▁ɛ | |
| a▁# | |
| a▁i | |
| i▁# | |
| b▁# | |
| ɛ▁# | |
| k▁e | |
| f▁e |
Nous observons le même modèle de distribution complémentaire que pour les nasales bilabiales : la latérale non voisée [l̥] apparaît en fin de mot lorsqu’elle est immédiatement précédée d’une obstruante non voisée, tandis que la latérale voisée apparaît partout ailleurs, soit après un phone voisé, soit avant un phone (pour l’empêcher d’être en fin de mot). Nous aboutirions à une analyse parallèle aux nasales, avec /l/ comme phonème, ayant un allophone non voisé [l̥] dans un environnement (fin du mot alors qu’il suit immédiatement une obstruante non voisée) et un allophone non voisé par défaut [l] partout ailleurs :
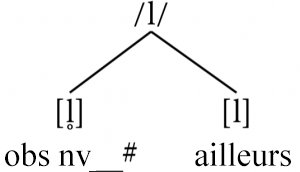
Répétez les étapes 2 à 6 pour [ʀ] et [ʀ̥]
Nous ferons ensuite la même chose pour [ʀ] et [ʀ̥], mais tout d’abord, notez comment /m/ et /l/ ont le même modèle de base : exactement le même type d’allophone (sans voix) dans le même environnement (en fin de mot immédiatement après une consonne non voisée), et exactement le même type d’allophone non voisé (voisé). Notez seulement que /m/ et /l/ font partie d’une classe naturelle : ce sont toutes deux des consonnes sonnantes. Mais la paire de phones restante que nous devons analyser, [ʀ] et [ʀ̥], sont également des consonnes sonnantes.
Il est peu probable qu’il s’agisse d’une coïncidence, et nous pouvons donc faire une prédiction, avant même d’examiner les données. Nous prédisons que [ʀ] et [ʀ̥] devraient se présenter comme les deux autres paires de sonantes, les deux phones étant distribués de manière complémentaire, le phone non voisé n’apparaissant qu’en fin de mot immédiatement après une obstruante non voisée et le phone voisé apparaissant ailleurs (après un phone voisé ou avant n’importe quel phone). Dans la liste suivante d’environnements pour [ʀ] et [ʀ̥], le modèle prédit est exactement ce que nous trouvons :
| [ʀ] | [ʀ̥] |
|---|---|
| #▁y | t▁# |
| ɛ▁# | f▁# |
| ɛ▁m | |
| i▁# | |
| v▁# | |
| t▁i | |
| #▁a | |
| #▁ɔ̃ | |
| k▁i | |
| ɔ▁d | |
| d▁# | |
| ɛ▁s |
Ainsi, nous aboutissons à la même analyse de base que pour les paires précédentes : les deux phones d’intérêt [ʀ] et [ʀ̥] sont des allophones de /ʀ/, l’allophone non voisé se produisant en fin de mot immédiatement après une obstruante non voisée et l’allophone voisé par défaut, se produisant partout ailleurs :
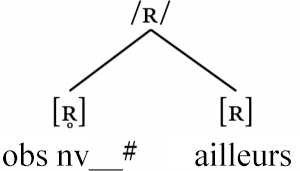
Y en a-t-il d’autres?
Cette analyse est intéressante, mais il semble qu’il nous manque encore quelque chose. Pourquoi ces trois phonèmes ont-ils le même modèle de base pour leurs allophones? Pourquoi ont-ils un allophone non voisé dans cet environnement particulier et pas ailleurs? Y a-t-il une raison pour que l’environnement de l’allophone non voisé mentionne également l’absence de voix? Rappelons que l’environnement de l’une des latérales géorgiennes partageait de manière similaire une propriété phonétique avec l’allophone qui s’y trouvait. Pouvons-nous d’une manière ou d’une autre représenter le schéma plus large de la distribution générale des sonantes en français? Pour l’instant, les distributions sont toujours précisées pour chaque phonème séparément, ce qui crée beaucoup de redondance dans notre analyse. La section suivante de notre analyse phonologique (section 4.7) permettra de répondre à ces questions!
Vérifiez votre compréhension
À venir!
Références
KATAMBA, Francis. 1989. An introduction to phonology. London : LONGMAN.
