Chapitre 4 : Phonologie
4.5 Analyse phonémique
Phonémisation
L’analyse phonémique est le processus d’analyse d’une langue parlée pour déterminer ses phonèmes, les allophones de ces phonèmes et la distribution de chaque allophone. L’analyse globale qui en résulte est appelée phonémisation de la langue.
Il convient de noter qu’une phonémisation donnée ne représente qu’une des nombreuses analyses possibles. Les langues n’ont généralement pas de phonémisation unique, car il existe de nombreuses façons de diviser les phones d’une langue en phonèmes.
De plus, étant donné que les phonèmes sont des concepts théoriques et abstraits, nous n’avons aucun moyen direct de vérifier si notre analyse est adéquate. En effet, certains linguistes rejettent complètement la notion de phonèmes, puisqu’il est possible d’analyser la phonologie d’une langue sans eux. Cependant, il existe des preuves expérimentales que les locuteurs utilisent quelque chose qui ressemble à un phonème, et jusqu’à ce que nous soyons capables d’ouvrir le cerveau humain et de découvrir exactement comment le langage est représenté, les phonèmes constituent une analyse raisonnable (voir le chapitre 13 pour obtenir plus d’informations).
Simplicité
Même si nous ne pouvons pas savoir si une phonémisation donnée, ou toute phonémisation en général, est adéquate, nous pouvons toujours comparer différentes analyses et déterminer celle qui est la mieux adaptée aux données et à nos hypothèses.
En particulier, si nous avons deux phonémisations concurrentes qui rendent toutes deux compte de l’ensemble des données disponibles, nous préférerons généralement l’analyse la plus simple (s’il y a lieu). Il s’agit du principe de simplicité. Cependant, il n’existe pas de mesure objective unique de la simplicité et il est parfois possible de proposer deux analyses concurrentes qui sont apparemment aussi simples l’une que l’autre. Dans de tels cas, nous pourrions nous appuyer sur d’autres facteurs, mais en fin de compte, nous serions normalement confrontés à une situation ambiguë.
Heureusement, les ensembles de données que vous voyez généralement dans un cours d’introduction à la linguistique ont été soigneusement sélectionnés pour présenter une phonémisation optimale évidente. Cependant, dans le monde réel, lorsque nous travaillons avec des données linguistiques brutes, il n’y a souvent pas d’analyses optimales évidentes, ce qui peut entraîner une moindre confiance dans les analyses que nous proposons.
Un exemple d’analyse phonémique : les latérales géorgiennes
Pour illustrer l’analyse phonémique, considérons les données suivantes du géorgien, une langue kartvélienne de la branche karto-zane, parlée en Géorgie (données adaptées de Kenstowicz et Kisseberth 1979).
| [vxlet͡ʃh] | « I split » | [saxɫʃi] | « at home » |
| [t͡ʃet͡ʃxli] | « fire » | [kaɫa] | « tin » |
| [zarali] | « loss » | [pepeɫa] | « butterfly » |
| [t͡ʃoli] | « wife » | [kbiɫs] | « tooth » |
| [xeli] | « hand » | [ɫxena] | « joy » |
| [kleba] | « reduce » | [erthxeɫ] | « once » |
| [leɫo] | « goal » | [xoɫo] | « however » |
| [ɫamazad] | « prettily » |
Étape 1 : Identifier et organiser les phones d’intérêt
Si nous n’avons pas en tête un ensemble particulier de phones ou si nous voulons phonémiser toute la langue, nous pouvons commencer par rechercher des paires minimales, ou commencer à analyser une petite classe naturelle simple, telles que les occlusives non voisées ou les voyelles antérieures. Dans les travaux d’introduction à la phonologie, les phones précis pour l’étude en cours vous sont habituellement fournis.
Pour cette démonstration, nous nous intéressons à deux phones en particulier : une approximante latérale alvéolaire [l] (souvent appelée [l] clair) et une approximante latérale alvéolaire vélarisée [ɫ] (souvent appelée [ɫ] sombre), où le dos de la langue est légèrement élevé vers le voile du palais en plus de l’articulation alvéolaire principale normale. De nombreux anglophones ont ces deux phones, avec un [l] clair au début d’un mot et un [ɫ] sombre à la fin, comme dans [lif] leaf vs [fiɫ] feel. En anglais, ces deux phones peuvent être considérés comme des allophones d’un seul phonème approximant latéral en raison de leur distribution complémentaire et de leur similarité phonétique; nous pouvons nous demander s’il en va de même en géorgien.
Une fois que nous avons sélectionné un ensemble de phones à étudier, nous pouvons les organiser par classes naturelles. S’il n’y en a que deux ou trois, aucun regroupement n’est normalement nécessaire. Mais si nous en avons quatre ou plus, cela peut s’avérer utile (nous devons le faire dans la section 4.6 ;pour un exemple en français).
Pour les approximantes latérales géorgiennes, nous devons également garder à l’esprit ce qui les différencie. Ici, la distinction se fait entre la position relevée du dos de la langue pour le [ɫ] sombre, et l’absence de relèvement du dos de la langue pour le [l] clair. Très souvent, nous constatons que la distribution d’un phone dépend de propriétés liées à son articulation. Ainsi, si [l] et [ɫ] ont une distribution complémentaire, nous pourrions nous attendre à ce que la position de l’arrière de la langue soit importante dans les phones avoisinants. Parfois, cependant, il n’y a pas de relation phonétique apparente entre les phones et leur environnement, de sorte que nous ne pouvons pas nous fier à cela en tant que stratégie universelle. Ainsi, en plus de prêter attention à la position de l’arrière de la langue dans l’environnement, il convient d’explorer d’autres facteurs qui pourraient également être pertinents.
Étape 2 : Identifier les environnements individuels des phones d’intérêt
En comprenant comment les phones qui nous intéressent sont liés les uns aux autres sur le plan phonétique, nous pouvons créer un diagramme avec les phones d’intérêt énumérés en haut. Ensuite, sous chaque phone, nous énumérons les différents environnements dans lesquels il apparaît, mot par mot.
La plupart du temps, il suffit de regarder ce qui se passe immédiatement à gauche et à droite d’un phone pour déterminer son environnement, mais il faut parfois prendre en compte d’autres informations, telles que la position syllabique, l’accent, le ton, ou même des phones plus éloignés. La plupart du temps, cependant, il suffit de regarder immédiatement à droite et à gauche.
Dans le but de rendre la notation plus concise lors de la construction de telles listes d’environnements, il est courant d’utiliser le symbole du croisillon # (également appelé carré ou dièse) pour marquer la frontière d’un mot et un trait de soulignement ▁ pour représenter la position du phone d’intérêt. Ainsi, « #▁a » pour [ɫ] indique qu’il existe un mot dans les données où [ɫ] est au début du mot et est suivi de [a], dans ce cas, [ɫamazad] « prettily ». En utilisant cette méthode pour [l] et [ɫ] en géorgien, nous obtiendrions les listes d’environnements suivantes :
| [l] | [ɫ] |
|---|---|
| x▁e | e▁o |
| x▁i | #▁a |
| a▁i | x▁ʃ |
| o▁i | a▁a |
| e▁i | e▁a |
| k▁e | i▁s |
| #▁e | #▁x |
| e▁# | |
| o▁o |
Chaque entrée de ces listes provient d’un ou de plusieurs mots. Le tout premier mot des données est [vxlet͡ʃh] (« I split »), qui contient [l] dans l’environnement x▁e, c’est-à-dire qu’il se trouve entre [x] et [e], nous inscrivons donc x▁e dans la colonne sous [l]. Le deuxième mot des données est [t͡ʃet͡ʃxli] (« fire »), qui contient [l] dans l’environnement x▁i, donc nous inscrivons x▁i dans la même colonne.
Nous continuons ainsi, mot par mot, en notant tous les environnements où nous trouvons chacun des phones d’intérêt. Veuillez noter que si un mot contient plusieurs occurrences de l’un des phones d’intérêt, nous indiquons tous les environnements pertinents. Nous le voyons avec le mot [leɫo] (« goal »), qui a l’environnement #▁e pour [l] et e▁o pour [ɫ], donc les deux sont notés dans leur liste respective.
Étape 3 : Déterminer le chevauchement des environnements
Nous voulons d’abord vérifier que les phones ne présentent pas de distribution contrastive évidente. Si les deux phones partagent certains environnements exactement identiques, il y a de fortes chances qu’ils soient des allophones de phonèmes distincts. Examinons maintenant si nous avons construit des listes similaires pour [p] et [k] en anglais. À un moment donné, nous aurions probablement des entrées comme #▁ɪ et s▁u pour les deux, à cause de mots comme pit, kit, spoon et school. Dans ce cas, nous conclurions probablement que les phones sont en distribution contrastive et devraient être analysés comme des allophones de phonèmes distincts. Ainsi, nous pourrions mettre fin à notre analyse de ces phones!
Cependant pour le géorgien, il faut continuer, car il n’y a pas de chevauchement apparent. Nous pourrions encore arriver à la conclusion que [l] et [ɫ] sont des allophones de phonèmes distincts, mais nous ne pouvons pas fonder cette décision sur un chevauchement d’environnements dans les données dont nous disposons ici.
Étape 4 : Simplifier les environnements
En observant la partie gauche des environnements des deux phones, nous constatons que les symboles sont souvent les mêmes : [x], [a], [e], [o] et #. Il n’y a pas beaucoup de cohérence du côté gauche et il n’y a pas de classes naturelles évidentes dans l’environnement gauche d’un phone par rapport à l’autre. Cependant, du côté droit de ces phones, nous observons une certaine répétition de phones et des classes naturelles au sein de chaque liste de phone, plutôt qu’entre les deux listes. Il semble donc que le côté droit de l’environnement puisse être déterminant pour découvrir une distribution complémentaire. Ainsi, nous pouvons simplifier notre analyse en ignorant l’environnement de gauche. Nous pouvons réécrire les listes en supprimant l’environnement de gauche et en éliminant toutes les entrées répétées, ce qui nous donne la liste d’environnements suivante, beaucoup plus simple :
| [l] | [ɫ] |
|---|---|
| ▁e | ▁o |
| ▁i | ▁a |
| ▁ʃ | |
| ▁s | |
| ▁x | |
| ▁# |
Il est maintenant beaucoup plus facile de voir quelles sont les distributions de ces deux phones : [l] n’apparaît que devant les voyelles antérieures [e] et [i], tandis que [ɫ] n’apparaît que devant la voyelle postérieure [o], la voyelle centrale [a], les fricatives non voisées [ʃ], [s] et [x], ainsi qu’à la fin du mot. Il s’agit d’une distribution complémentaire classique, car ce sont des environnements exactement opposés : les voyelles antérieures ne sont pas des voyelles postérieures ou centrales, elles ne sont pas des fricatives non voisées et elles ne se trouvent pas en position de fin de mot. Aucun des deux phones d’intérêt ne semble pouvoir apparaître dans l’environnement de l’autre.
Vous remarquerez que ce schéma correspond également à notre hypothèse préliminaire de l’étape 1 selon laquelle la distribution de ces deux phones pourrait avoir un rapport avec la position de l’arrière de la langue, puisque c’est précisément la caractéristique qui différencie certains de ces environnements, en particulier les voyelles antérieures par rapport aux voyelles postérieures.
Étape 5 : Organiser les phones en phonèmes
Étant donné que [l] et [ɫ] semblent être en distribution complémentaire, nous pourrions penser qu’il s’agit d’allophones d’un même phonème. La question est de savoir s’ils se comportent davantage comme des sons distincts tels que [h] et [ŋ] en anglais (que les locuteurs considèrent généralement comme appartenant à des phonèmes différents) ou comme des sons similaires tels que [iː] et [i] en anglais (que les locuteurs considèrent comme appartenant au même phonème). Il n’est pas toujours évident de savoir ce qu’il faut faire dans un cas donné, mais nous recherchons généralement une similarité phonétique.
Les latérales géorgiennes présentent de nombreuses similarités phonétiques : elles ont la même phonation (voisée), le même lieu d’articulation (alvéolaire) et le même mode d’articulation (approximante latérale); elles diffèrent uniquement par l’articulation secondaire (vélarisée ou non). Ainsi, nous avons à la fois une distribution complémentaire et un degré élevé de similarité phonétique, de sorte qu’il semble raisonnable d’analyser [l] et [ɫ] comme des allophones d’un même phonème.
Étape 6 : Identifier l’allophone par défaut et achever l’analyse
L’allophone par défaut d’un phonème est celui qui apparaît dans la plus grande variété d’environnements, ce que nous appelons parfois le cas « ailleurs ». Pour les approximantes latérales géorgiennes, l’allophone par défaut est manifestement [ɫ], car il apparaît dans de nombreux environnements distincts, tous différents les uns des autres. Par convention, nous utilisons normalement le symbole de l’allophone par défaut pour représenter le phonème, à moins qu’il n’y ait une bonne raison de faire autrement. Ici, nous représenterons donc le phonème contenant [l] et [ɫ] par /ɫ/ puisque [ɫ] est l’allophone par défaut.
Notez que le phonème /ɫ/ et le phone [ɫ] sont des objets de nature différente, donc cette différence de notation est essentielle. Les phonèmes sont des abstractions théoriques qui peuvent également correspondre à une sorte de représentation mentale, tandis que les allophones sont des phones, ce qui signifie qu’il s’agit de sons concrets et mesurables qui sont physiquement produits. Le phonème /ɫ/ correspond à l’ensemble des allophones [l] et [ɫ], avec [l] apparaissant devant les voyelles antérieures et l’allophone par défaut [ɫ] apparaissant ailleurs.
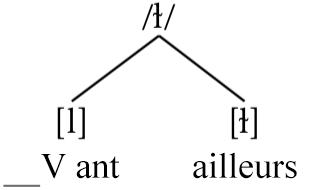
Les phonèmes et leurs allophones sont souvent représentés graphiquement dans un diagramme arborescent, tel que le diagramme pour /ɫ/ présenté à la figure 4.1. Ici, nous abrégeons informellement « devant les voyelles antérieures » par ▁V ant. pour économiser de l’espace dans l’arbre.
Prédictions
Cette analyse permet de faire des prédictions sur les latérales en géorgien au-delà de ce que nous voyons dans les données fournies. Nous nous attendons à ce que chaque [l] clair en géorgien soit suivi d’une voyelle antérieure, et à ce que chaque [ɫ] sombre en géorgien soit suivi d’autre chose qu’une voyelle antérieure. Toutes les données que nous avons examinées sont en accord avec ces prédictions, mais nous pourrions encore nous tromper si nous trouvions de nouveaux éléments qui contredisent notre analyse.
Par exemple, nous prédisons que [ɫ] devrait pouvoir apparaître devant n’importe quelle consonne, et pas seulement devant les fricatives non voisées, parce qu’il s’agit du cas par défaut et qu’il devrait apparaître dans la plus grande variété d’environnements, alors que le [l] clair est limité à apparaître uniquement devant les voyelles antérieures. Il s’agit d’une prédiction vérifiable! Nous pouvons chercher d’autres mots géorgiens et voir quel type de latérale nous trouvons devant d’autres consonnes. Conformément à notre prédiction, nous ne trouvons que des [ɫ] sombres devant les consonnes, comme dans [aɫq’a] (« siege »), qui ne peut pas être prononcé *[alq’a] avec un [l] clair.
Vérifiez votre compréhension
À venir!
Références
Kenstowicz, Michael, and Charles Kisseberth. 1979. Generative phonology: Description and theory. New York: Academic Press.
