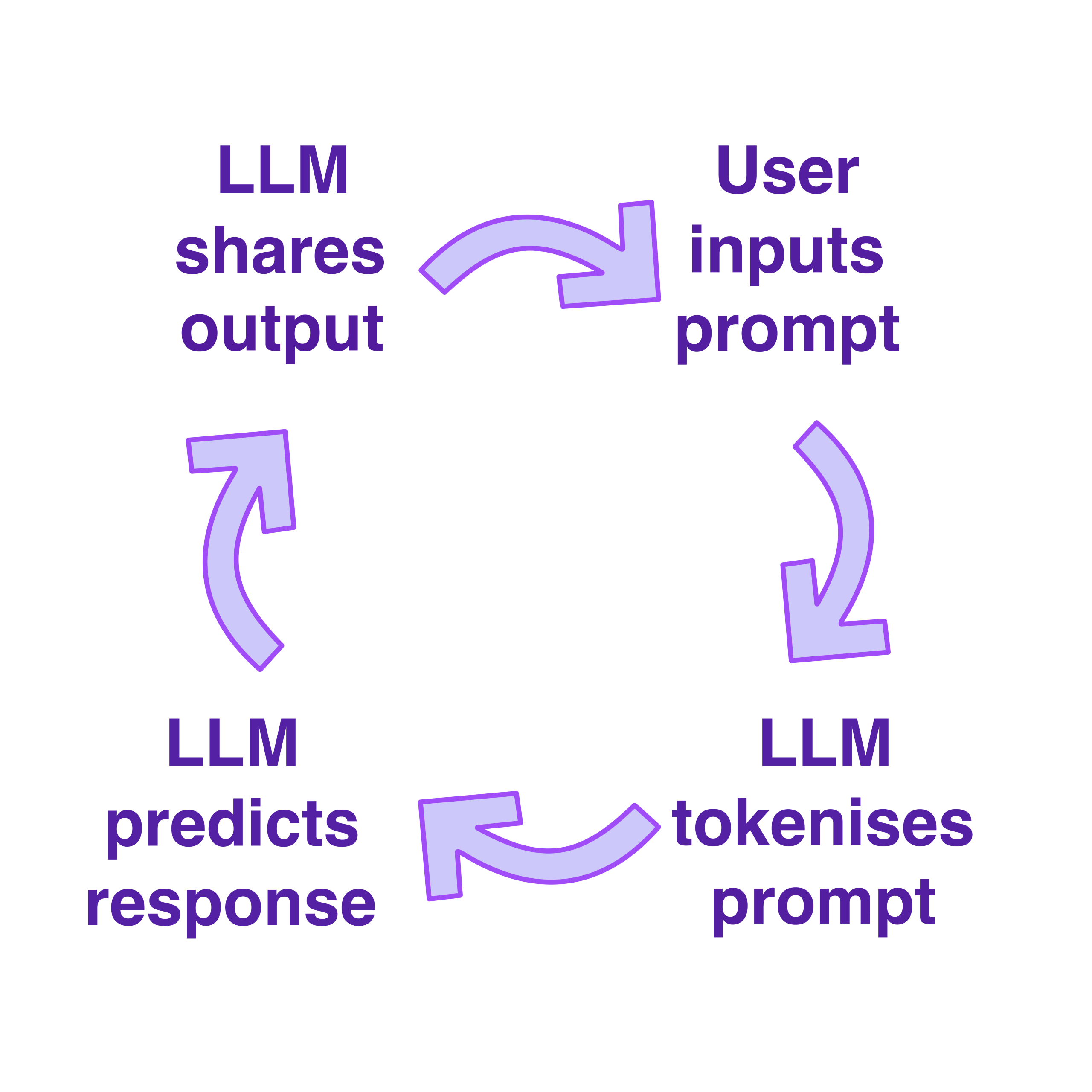
1.2 What do we know about how large language models work?

What do we know about how large language models work?
Training
The AI model is pre-trained on a large dataset, typically of general texts or images. For specialized AI models, they may be trained on a specific dataset of subject or domain specific data. The AI analyses the data, looking for patterns, themes, relationships and other characteristics that can be used to generate new content.
For example, early models of GPT (the LLM used by both ChatGPT and Copilot) were trained on hundreds of gigabytes of text data, including books, articles, websites, publicly available texts, licensed data, and human-generated data.
Human intervention can occur at all stages of the training.
Humans may:
- Create and modify the initial dataset, removing messy or problematic data
- Assess the quality of output from the AI model
The model is then released for use and can be accessed by users
Generation
LLMs generate text in response to a user-provided prompt.
Prompting
A user provides a prompt, asking the AI model to perform a specific task, generate text, produce an image, or create other types of content.
Prompt: Tell me a joke about higher education.
Tokenization
The AI breaks the prompt into tokens (words or parts of words or other meaningful chunks) and analyses these tokens in order to understand the meaning and context of what is being asked.
Token Breakdown: ["Tell", "me", "a", "joke", "about", "higher",
"education", "."]
NOTE: words might also be broken into subword tokens like “high”, “er”, “edu”, “cation”]
These tokens are then converted into vectors (numerical values) that represented the position of the token in relationship to other tokens, representing how likely they are to occur in sequence.
Prediction
The LLM analyses the vectors and, based on the patterns and other information learned in training, the AI model will start to predict a response to the prompt based on the probability of response tokens appearing in sequence.
For example, in responding to our request to generate a joke, the most likely starting token may be “Why”, “What”, “Here’s” etc.
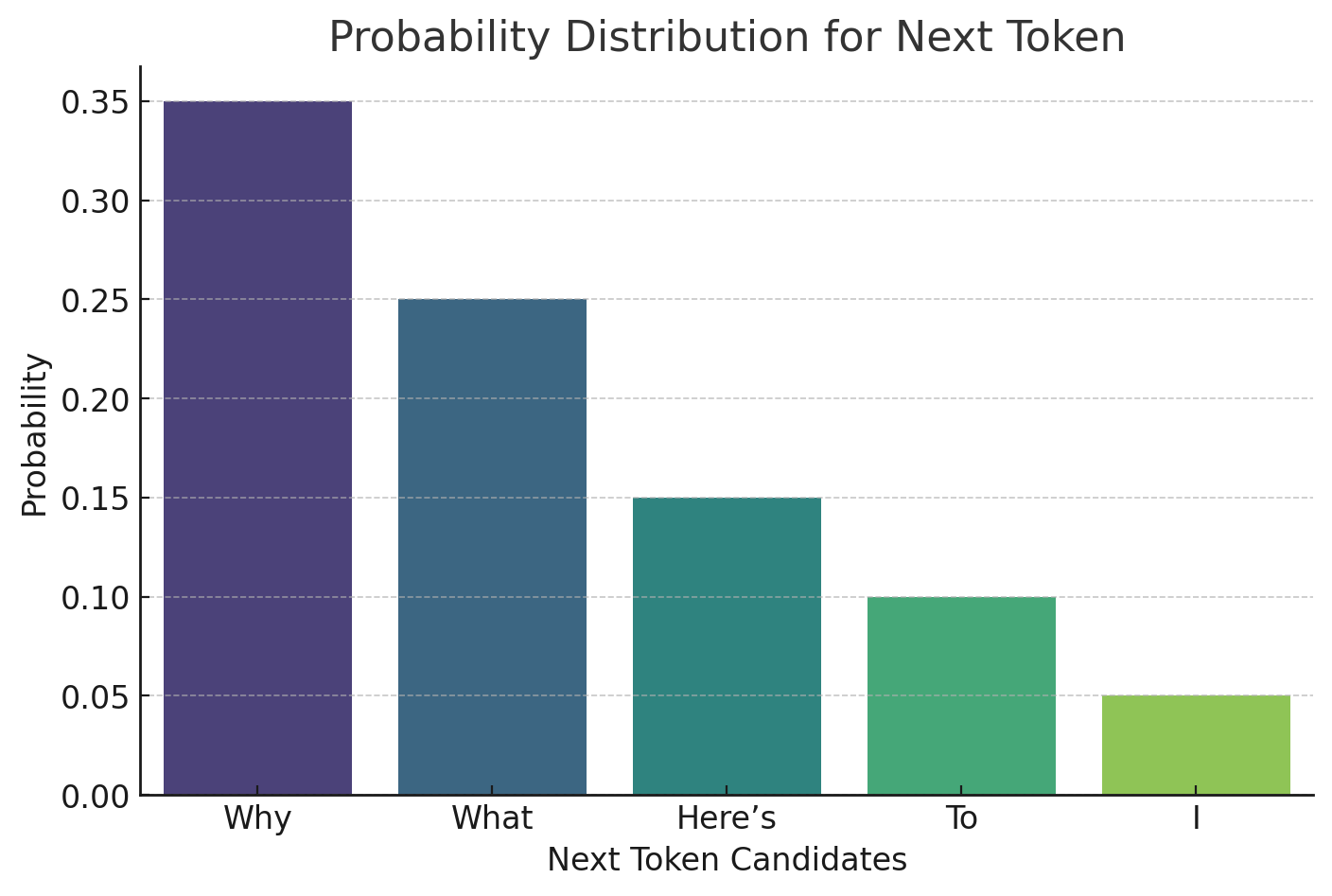
Although Large Language Models do generate output based on probability, they do this using millions or billions of parameters, so often the process of generating is so complex that creators and users don’t really know how they work. This opaqueness is why AI systems are often referred to as a black box, making generative AI systems vulnerability to unseen biases, vulnerabilities, and other problems.
Output
After predicting a sequence of tokens, the LLM decodes the tokens back into natural language (words and sentences readable by a human). The complete response is shared with the user.
✅ “Why did the student bring a ladder to class? To reach higher education!”
The user can then submit a follow-up request referencing the original request or output. This is called iteration.
For more a more detailed introduction to generative AI, see this video from Google:
For a more in-depth look at how LLMs function, see this article from the Financial Times:
Generative AI exists because of the transformer ![]()
What are the Limitations of Large Language Models?
Generative AI is evolving quickly but still has certain limitations. Large Language Models (LLMs) are constrained by the data upon which they are trained and the methods through which they are trained. It’s important to be aware of the limitations of the tools that you’re using, especially if currency or accuracy is important for the tasks that you’re using generative AI to complete.
- We do not fully understand how LLMs work, which presents issues for safety, reliability and accuracy.
- LLMs are susceptible to hallucinations or the creation of nonsensical words, phrases, or ideas. This can also result in the generation of non-existent references
 .
. - Many LLMs are pre-trained and have knowledge cut-off dates, meaning that data may be out of date or inaccurate. However, increasingly generative AI tools are able to access and process information in real time. This is called Retrieval Augmented Generation (RAG).
- There is a trade-off between processing speed and accuracy with LLMs. Many basic models do not fact-check, meaning that the information that they share is not guaranteed to be accurate or logical. These models produce much faster results at the risk of lower accuracy. Reasoning models have increased accuracy because they break tasks down into micro-steps, apply logic, and evaluate possible results. However, they have longer processing times and require significantly more resources. They are also not immune to making mistakes.
- Standard LLMs produce output based on averages or probabilities of patterns, so they are susceptible to reproducing biases found in their data sets, including but not limited to biases based on human biases that may be embedded in historical records, cultures, patterns of research, societal norms, and any other elements reflected in the text data used for their training. This will be discussed more in the Ethics section.
LLMs are trained on massive amounts of text before they are released to allow them to learn patterns and relationships.
A prompt is the text that is provided to the system providing instructions on the desired output or the task being requested.
Computational models that are trained on huge datasets of text to recognize common patterns and relationships in natural language. They can be used for generating texts that mimic human language.
Nonsensical outputs, such as words or phrases that don’t exist, grammatically incorrect text, references to articles or resources that don’t exist, or warped images.

Feedback/Errata